3 分布式计算与资源调度
分布式计算概述
什么是分布式计算
由数据得到的结论是广义上的计算,也是计算的目的
分布式计算是指以分布式的形式完成数据的统计,得到结果
- 数据过大无法一台电脑独立计算
- 用数量取胜单台计算
分布式计算模式
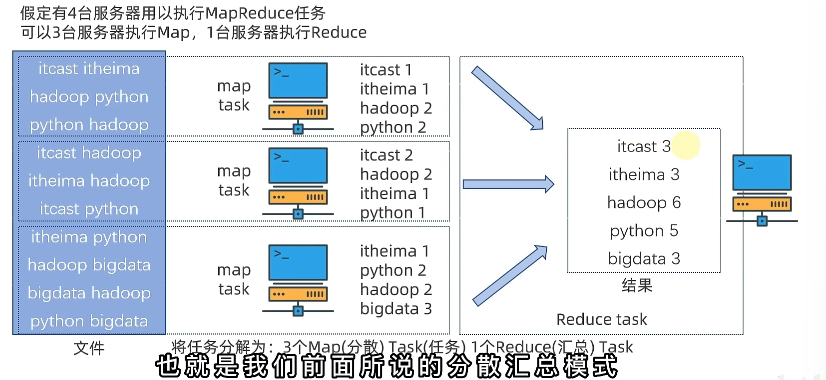
分散-汇总模式(MapReduce)
- 分发数据,多台服务器各自负责一部分的数据处理
- 汇总到一台主机
中心调度-步骤执行模式(Spark、Flink)
在计算的中间结果有数据交换的过程
- 由一个节点作为中心调度管理者
- 划为几个步骤
- 安排每台机器的执行与数据交换
MapReduce
是Hadoop组件之一

MapReduce 提供了两个编程接口:
- Map 提供分散数据功能
- Reduce 汇总聚合功能
执行原理
提示
Hive 是基于MapReduce的sql计算框架
YARN
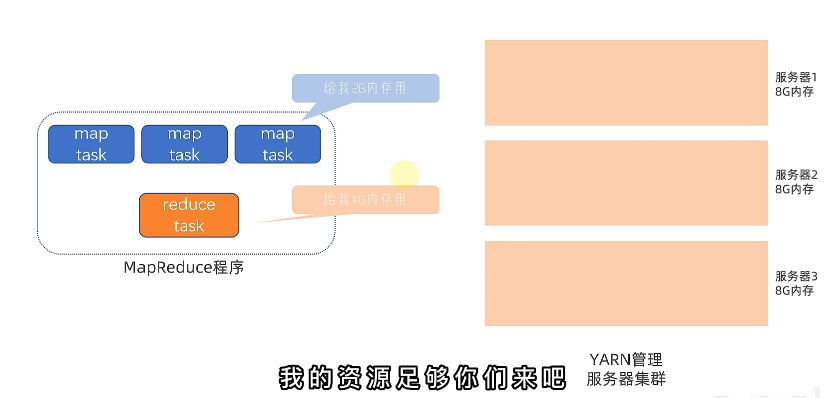
YARN 与 MapReduce 会一起执行,用于资源调度
分布式服务器资源调度,对整个服务器进行统一调度,对资源有规划有管理的使用,能提高效率。
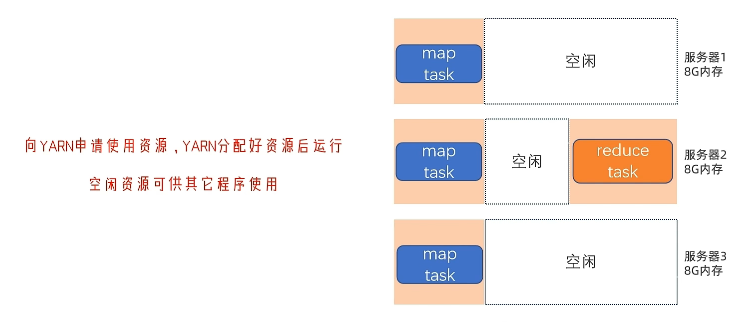
YARN下MapReduce的调度
YARN架构
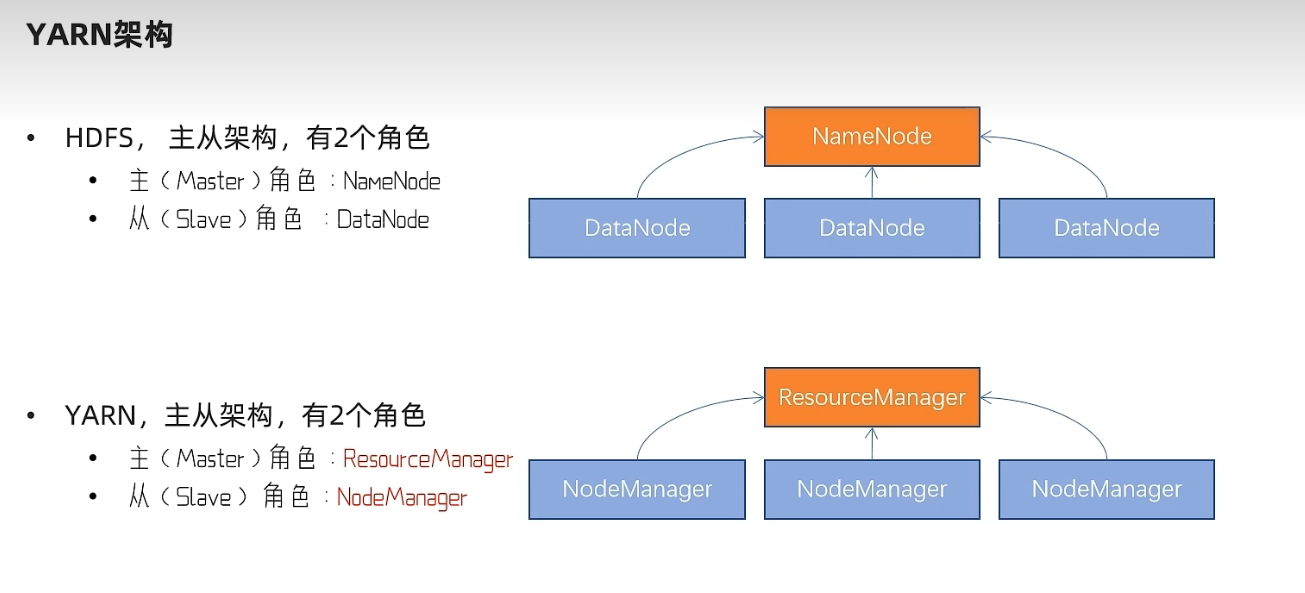
- RescourceManager:整个集群的资源调度者
- NodeManager:单个服务器的资源调度者
YARN容器
- 预先先占用资源,再分配给任务
- 虚拟化计算,封装运行(NodeManager)
YARN辅助角色
- 代理服务器,提高网络访问的安全
- JobHistoryServer历史服务器,通过收集容器的日志,通过浏览器访问
配置MapReduce与部署YARN
修改部分

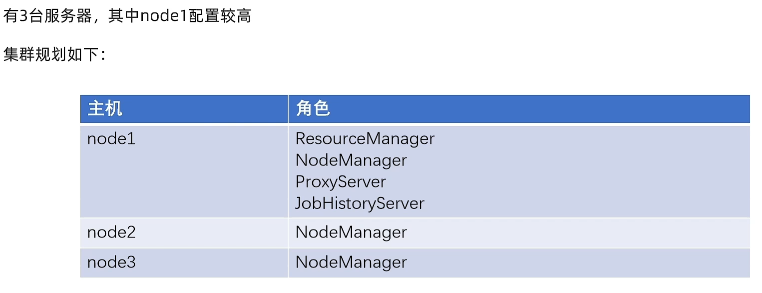
集群规划:
MapReduce的配置
添加 mapred-env.sh 配置(/etc/hadoop)
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPREN_ROOT_LOGGER=LNFO,RFA
添加 mapred-site.xml 配置(/etc/hadoop)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10820</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
YARN配置文件
添加 mapred-env.sh 配置(/etc/hadoop)
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
添加 yarn-site.xml 配置(/etc/hadoop)
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
开始计算
提交MapReduce至YARN运行
MapReduce实例代码
- wordcount: 单词计数器
- pi:求圆周率
求单词计数的执行过程
- 把需要统计的文本放置在hdfs文件系统
- 执行以下命令进行文件单词统计
[hadoop@node1 ~]$ hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount hdfs://node1:8020/input/ hdfs://node1:8020/output/hl
提示
其中/input/的意思是统计该目录下的所有文件
求PI的执行过程
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar pi 3 10000
结果:
2023-06-18 14:06:45,427 INFO mapreduce.Job: map 0% reduce 0%
2023-06-18 14:07:01,534 INFO mapreduce.Job: map 67% reduce 0%
2023-06-18 14:09:57,239 INFO mapreduce.Job: map 78% reduce 0%
2023-06-18 14:09:58,243 INFO mapreduce.Job: map 89% reduce 0%
2023-06-18 14:10:13,294 INFO mapreduce.Job: map 89% reduce 22%
2023-06-18 14:10:16,305 INFO mapreduce.Job: map 100% reduce 22%
2023-06-18 14:10:17,309 INFO mapreduce.Job: map 100% reduce 100%
2023-06-18 14:10:17,314 INFO mapreduce.Job: Job job_1687019957893_0008 completed successfully
2023-06-18 14:10:17,457 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=72
FILE: Number of bytes written=1109437
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=783
HDFS: Number of bytes written=215
HDFS: Number of read operations=17
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=589338
Total time spent by all reduces in occupied slots (ms)=17633
Total time spent by all map tasks (ms)=589338
Total time spent by all reduce tasks (ms)=17633
Total vcore-milliseconds taken by all map tasks=589338
Total vcore-milliseconds taken by all reduce tasks=17633
Total megabyte-milliseconds taken by all map tasks=603482112
Total megabyte-milliseconds taken by all reduce tasks=18056192
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=54
Map output materialized bytes=84
Input split bytes=429
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=84
Reduce input records=6
Reduce output records=0
Spilled Records=12
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=669
CPU time spent (ms)=590390
Physical memory (bytes) snapshot=1938477056
Virtual memory (bytes) snapshot=12350963712
Total committed heap usage (bytes)=1853358080
Peak Map Physical memory (bytes)=625938432
Peak Map Virtual memory (bytes)=3091316736
Peak Reduce Physical memory (bytes)=286851072
Peak Reduce Virtual memory (bytes)=3089543168
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=354
File Output Format Counters
Bytes Written=97
Job Finished in 220.245 seconds
Estimated value of Pi is 3.14159264764749259810