3 分布式计算SQL体系
Hive
主要功能是将SQL翻译成MapReduce
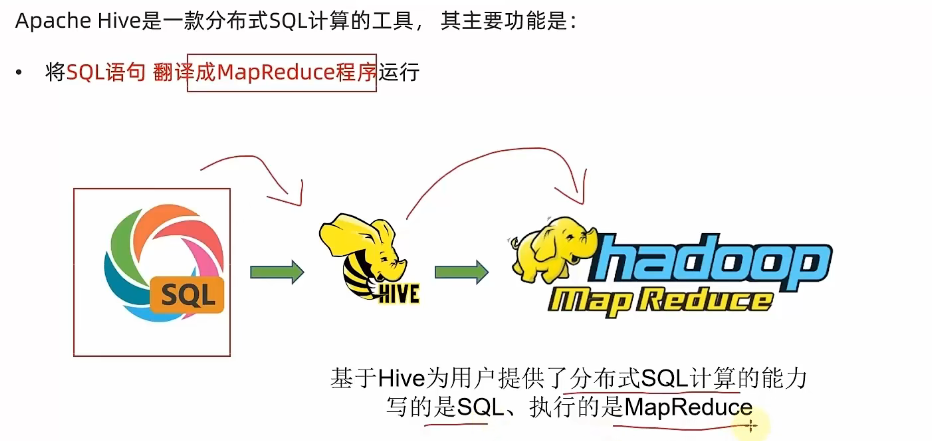
模拟实现Hive

针对SQL:
SELECT city, COUNT(*) FROM t_user GROUP BY city

提示
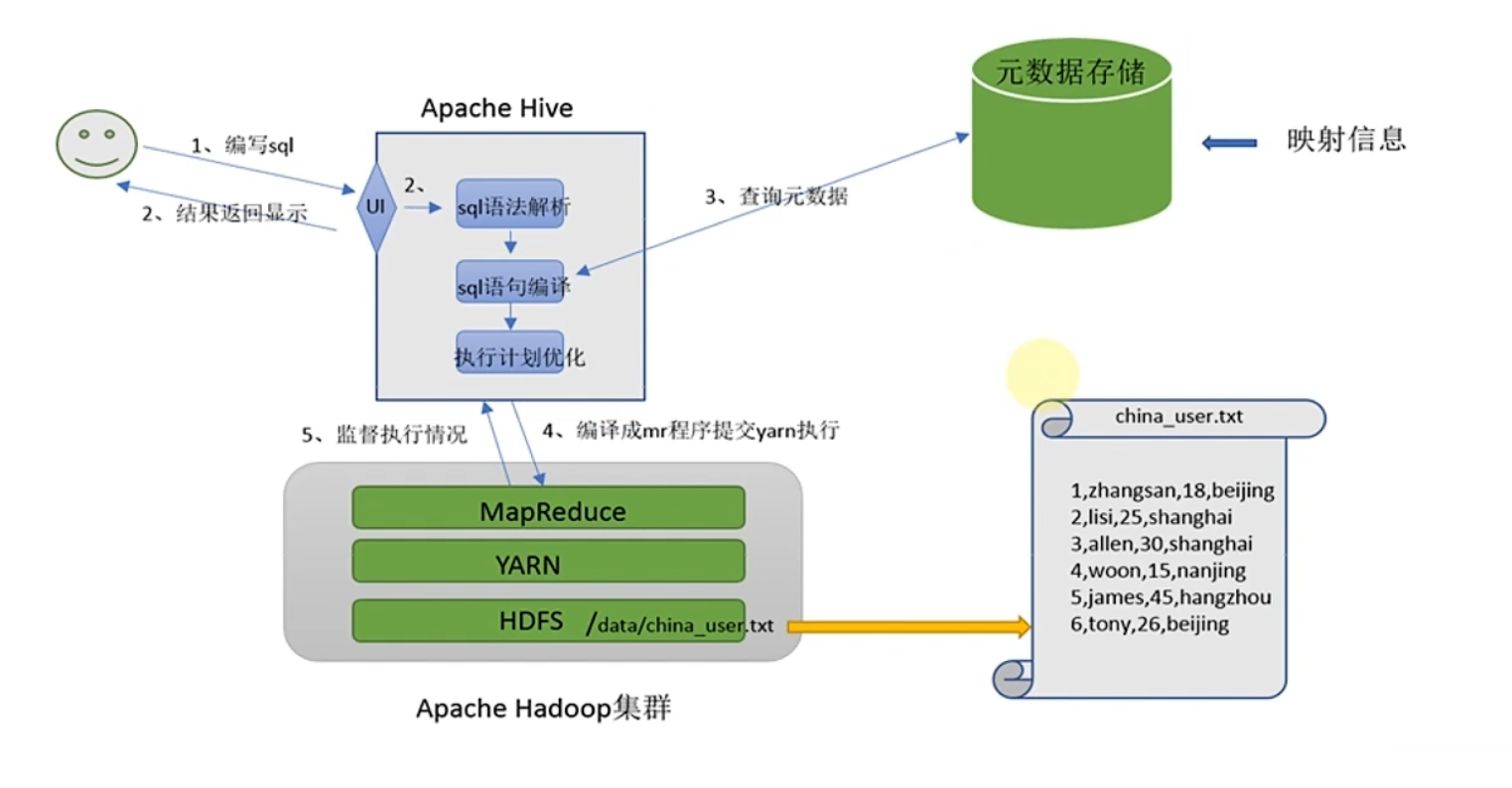
针对文本文件,需要对文件生成映射才可以查找计算
针对以上分析构建SQL计算,需要拥有:
- 元数据管理功能(数据位置,数据文件,数据描述)
- SQL解析器(分析SQL,SQL转换MR)
Hive 基础架构
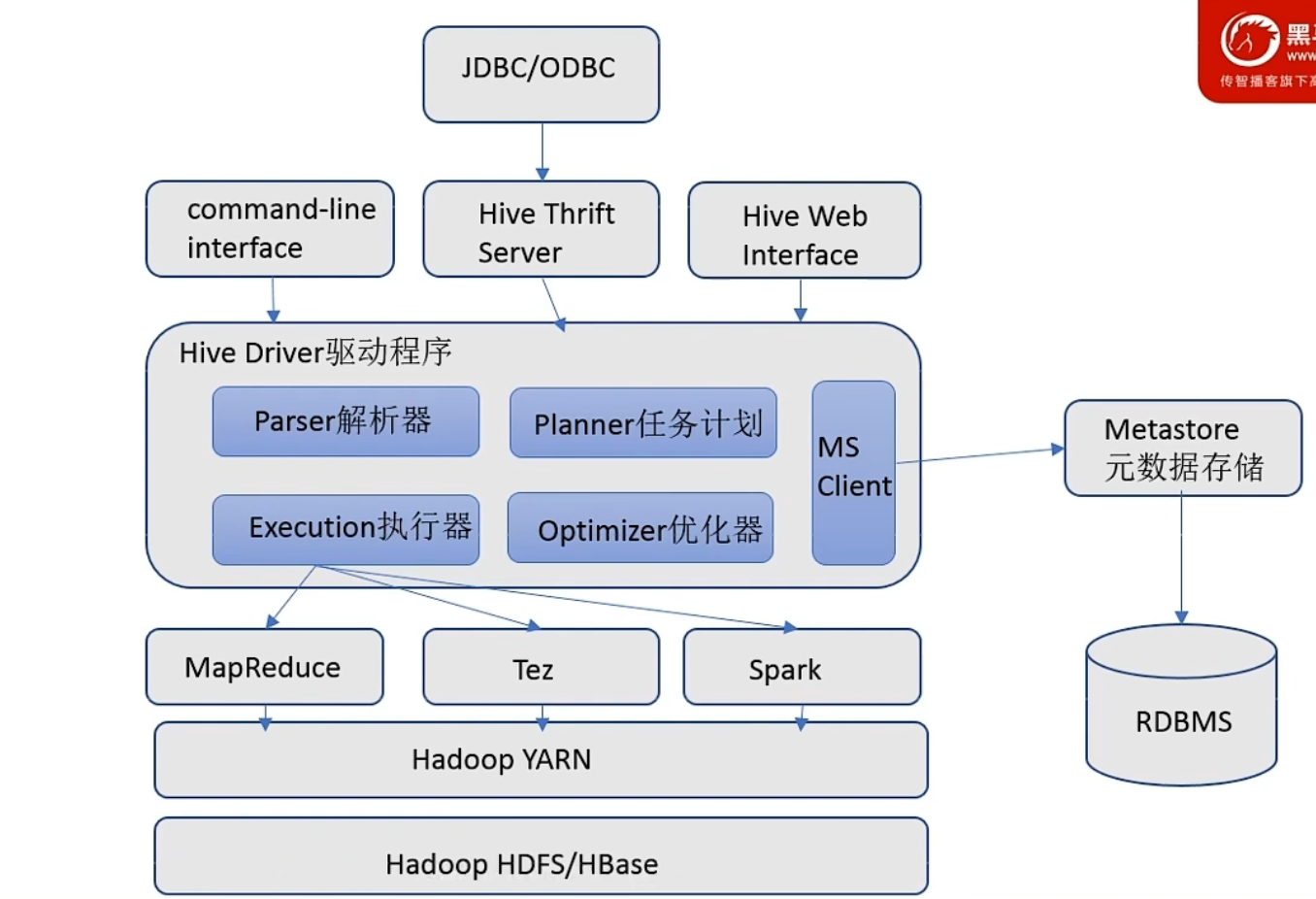
- Metastore-元数据存储
- Driver驱动程序(SQL解析器)
- 用户接口
Hive 部署
提示
Hive 本身是单机工具,只需部署在一台服务器上
规划
| 服务 | 机器 |
|---|---|
| Hive程序 | 部署在node1 |
| 关系性数据库(元数据映射) | 部署在node1 |
配置文件
/hive/conf/hive-env.shsh
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
/hive/conf/hive-site.xmlxml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--连接数据的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--连接数据的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!--mysql数据库的访问路径,没有路径则自动创建-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://guet.gxist.cn:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!--连接数据库的驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--元数据是否校验-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--是否自动创建核心文件-->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<!--thrift服务器绑定的主机-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!--默认的存储地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!--设置显示表头字段名-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
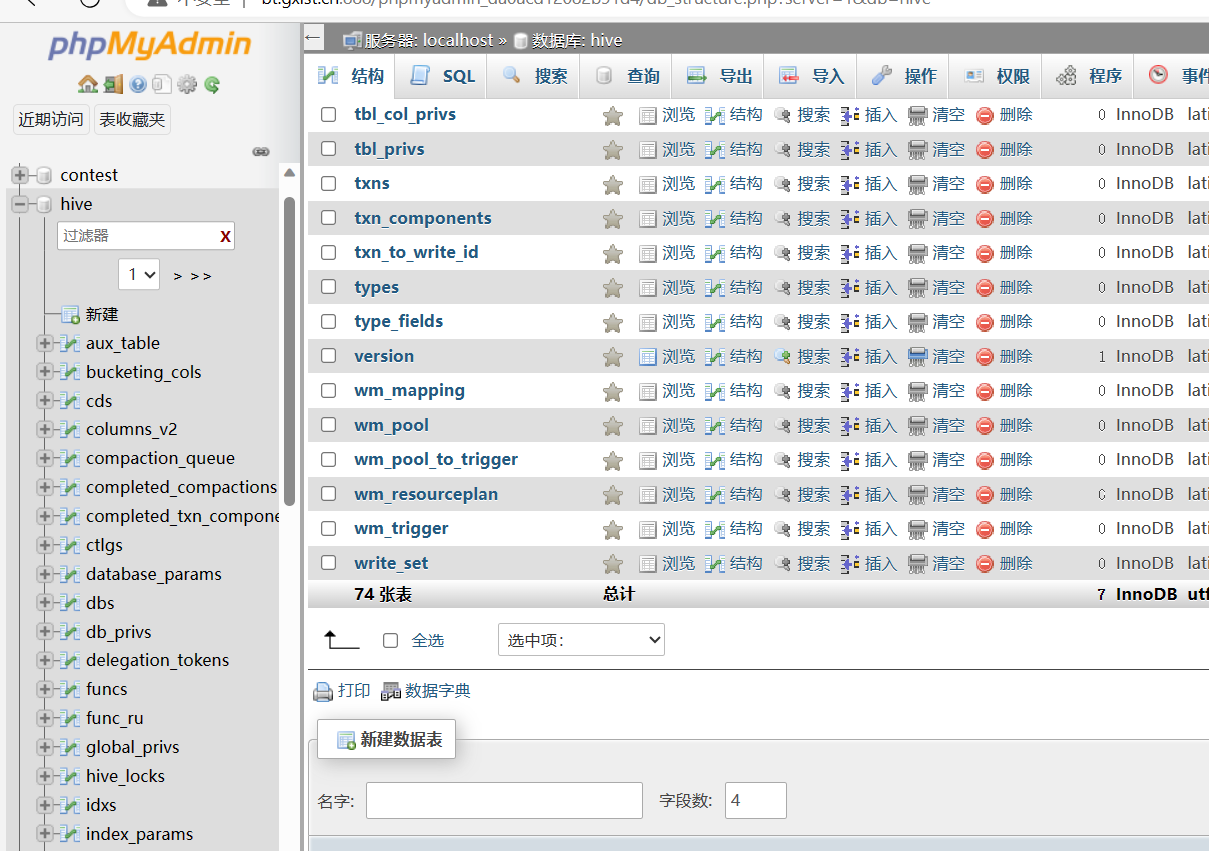
初始化元数据表
[hadoop@node1 hive]$ ./bin/schematool -initSchema -dbType mysql -verbos
初始脚本总共有74张表:
启动服务
[hadoop@node1 hive]$ nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
进入hive Shell
[hadoop@node1 hive]$ bin/hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
/usr/bin/which: no hbase in (/home/hadoop/.local/bin:/home/hadoop/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/export/server/jdk/bin:/export/server/hadoop/bin:/export/server/hadoop/sbin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 8e6c9071-e6a9-4006-89f8-f8dd90b9c5aa
Logging initialized using configuration in jar:file:/export/server/apache-hive-3.1.3-bin/lib/hive-common-3.1.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = 22c5984f-3b8a-49c4-bdb8-5f9d16c18f4a
hive (default)> show databases;
OK
database_name
default
Time taken: 0.761 seconds, Fetched: 1 row(s)
hive (default)>
看到显示hive (default)> 代表成功进入hive数据库。
hive 启动方式
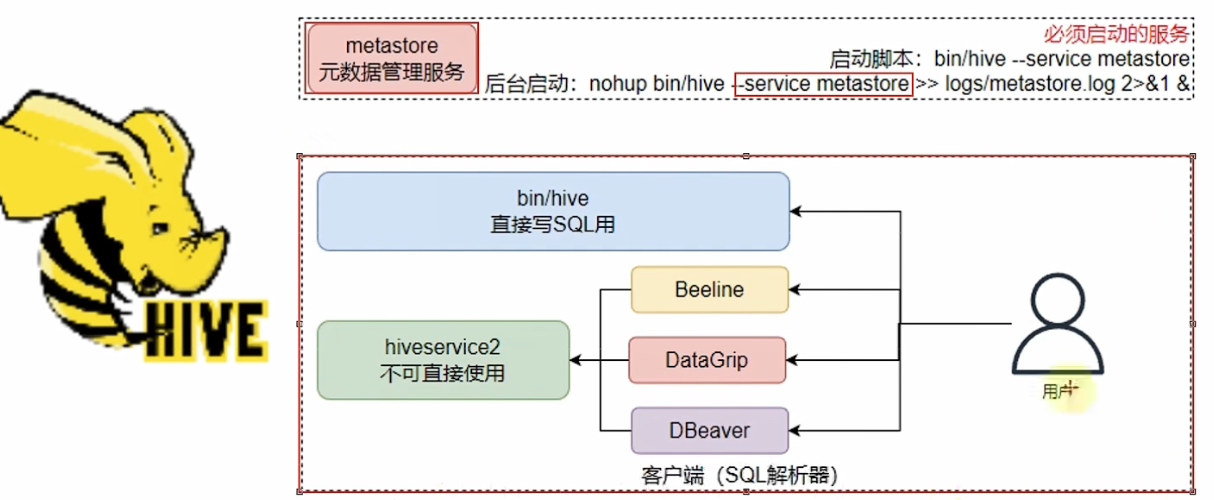
Shell启动
创建表
hive (default)> create table test(id int,name string,gender string);
OK
Time taken: 1.111 seconds
插入表
hive (default)> insert into test values(1,"wrm244","boy");
Query ID = hadoop_20230622000808_9ec885e7-fe6b-4d66-ab3a-1531571347dd
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1687019957893_0009, Tracking URL = http://node1:8089/proxy/application_1687019957893_0009/
Kill Command = /export/server/hadoop/bin/mapred job -kill job_1687019957893_0009
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2023-06-22 00:08:27,119 Stage-1 map = 0%, reduce = 0%
2023-06-22 00:08:40,535 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.64 sec
2023-06-22 00:08:51,842 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.94 sec
MapReduce Total cumulative CPU time: 7 seconds 940 msec
Ended Job = job_1687019957893_0009
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://node1:8020/user/hive/warehouse/test/.hive-staging_hive_2023-06-22_00-08-08_904_1474593618908524738-1/-ext-10000
Loading data to table default.test
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.94 sec HDFS Read: 16372 HDFS Write: 278 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 940 msec
OK
col1 col2 col3
Time taken: 45.011 seconds
hive (default)> select * from test
> ;
OK
test.id test.name test.gender
1 wrm244 boy
Time taken: 0.167 seconds, Fetched: 1 row(s)
提示
我们可以发现当执行插入操作的时候,会执行MapReduce计算存储数据,所以时间比较长。
hive通过sql存在hdfs文件系统中
路径为/user/hive/warehouse
[hadoop@node1 hive]$ hadoop fs -ls /user
Found 2 items
drwx------ - hadoop supergroup 0 2023-06-18 14:10 /user/hadoop
drwxr-xr-x - hadoop supergroup 0 2023-06-22 00:04 /user/hive
[hadoop@node1 hive]$ hadoop fs -ls /user/hive
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2023-06-22 00:04 /user/hive/warehouse
[hadoop@node1 hive]$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2023-06-22 00:08 /user/hive/warehouse/test
[hadoop@node1 hive]$
文件内容:
[hadoop@node1 hive]$ hadoop fs -cat /user/hive/warehouse/test/*
1wrm244boy
[hadoop@node1 hive]$
客户端启动
[hadoop@node1 hive]$ nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
[2] 311374
[hadoop@node1 hive]$ cat ./logs/hiveserver2.log
nohup: 忽略输入
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
/usr/bin/which: no hbase in (/home/hadoop/.local/bin:/home/hadoop/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/export/server/jdk/bin:/export/server/hadoop/bin:/export/server/hadoop/sbin)
2023-06-22 00:27:41: Starting HiveServer2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 67a03039-6e14-470b-be62-c776e432b606
Hive Session ID = 77346be8-b413-49b4-9b56-e34eed3f56b6
[hadoop@node1 hive]$ jps
106128 NodeManager
105970 ResourceManager
106647 WebAppProxyServer
105161 DataNode
104984 NameNode
311374 RunJar
303496 RunJar
105580 SecondaryNameNode
107212 JobHistoryServer
311753 Jps
[hadoop@node1 hive]$ ps -ef | grep 311374
- 对外提供端口
:1000
[hadoop@node1 hive]$ netstat -anp | grep 10000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::10000 :::* LISTEN 311374/java
使用beeline客户端
[hadoop@node1 hive]$ bin/beeline
beeline> !connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: hadoop
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> show databases
. . . . . . . . . . . . . .> ;
INFO : Compiling command(queryId=hadoop_20230622003526_dae4b43d-e10d-4939-a70b-3f0b1b5774f6): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20230622003526_dae4b43d-e10d-4939-a70b-3f0b1b5774f6); Time taken: 1.034 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hadoop_20230622003526_dae4b43d-e10d-4939-a70b-3f0b1b5774f6): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20230622003526_dae4b43d-e10d-4939-a70b-3f0b1b5774f6); Time taken: 0.076 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.619 seconds)