搜索配置
搜索功能是基于 algolia 来进行配置,配置方式有两种:
-
让
Docsearch每周爬一次你的网站,前提条件是你的项目必须是开源的,否则要进行收费,好处是没有额外的配置,只不过申请比较繁琐。 -
自己运行
Docsearch爬虫,根据自己心情随时爬取,但是需要自行注册账号和搭建爬虫环境(docker),这也是我目前选择的方式。
在开始以下步骤之前请先阅读 搜索|Docusaurus 进行基本的配置
下面只介绍我所采用的配置方式,原本采用的是第一种方案,后来因申请时间有点久边选择了第二种方案
第一种方案
你可以先试着用第一种方案申请一下,进入 Algolia DocSearch 的申请地址,填写相关信息,需要注意的是,网站要可以公开访问的
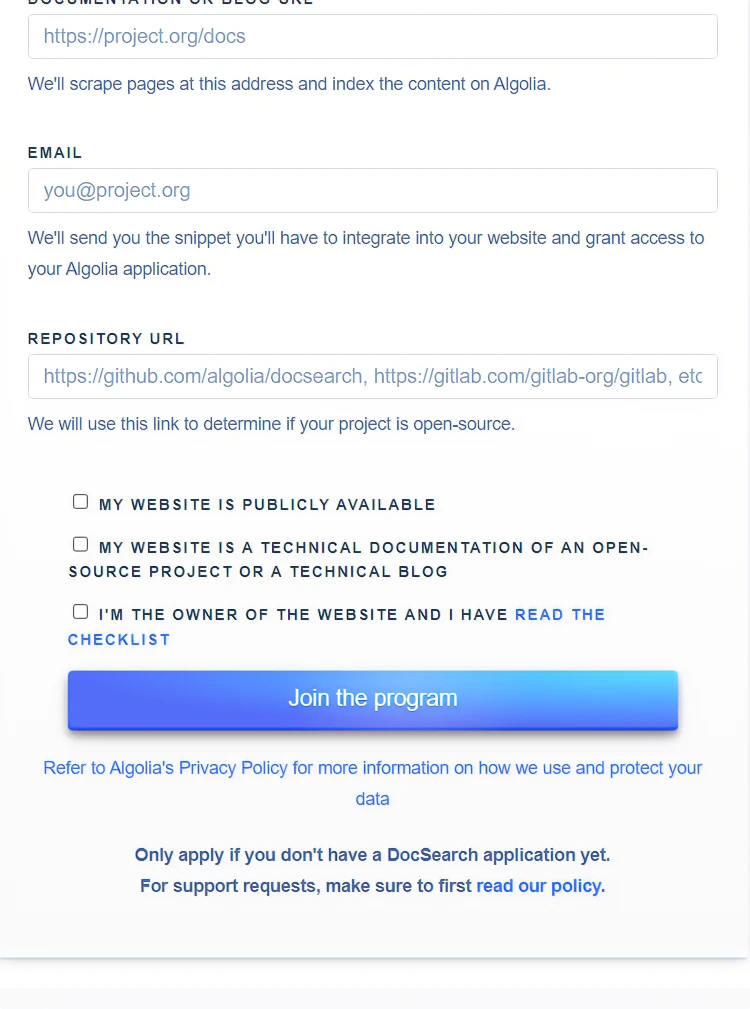
申请的过程可能比较麻烦和耗时,但他是免费的,而且一劳永逸(如果你不想折腾自己运行爬虫的话)
然而申请结果邮件,最终是等了三四天才收到
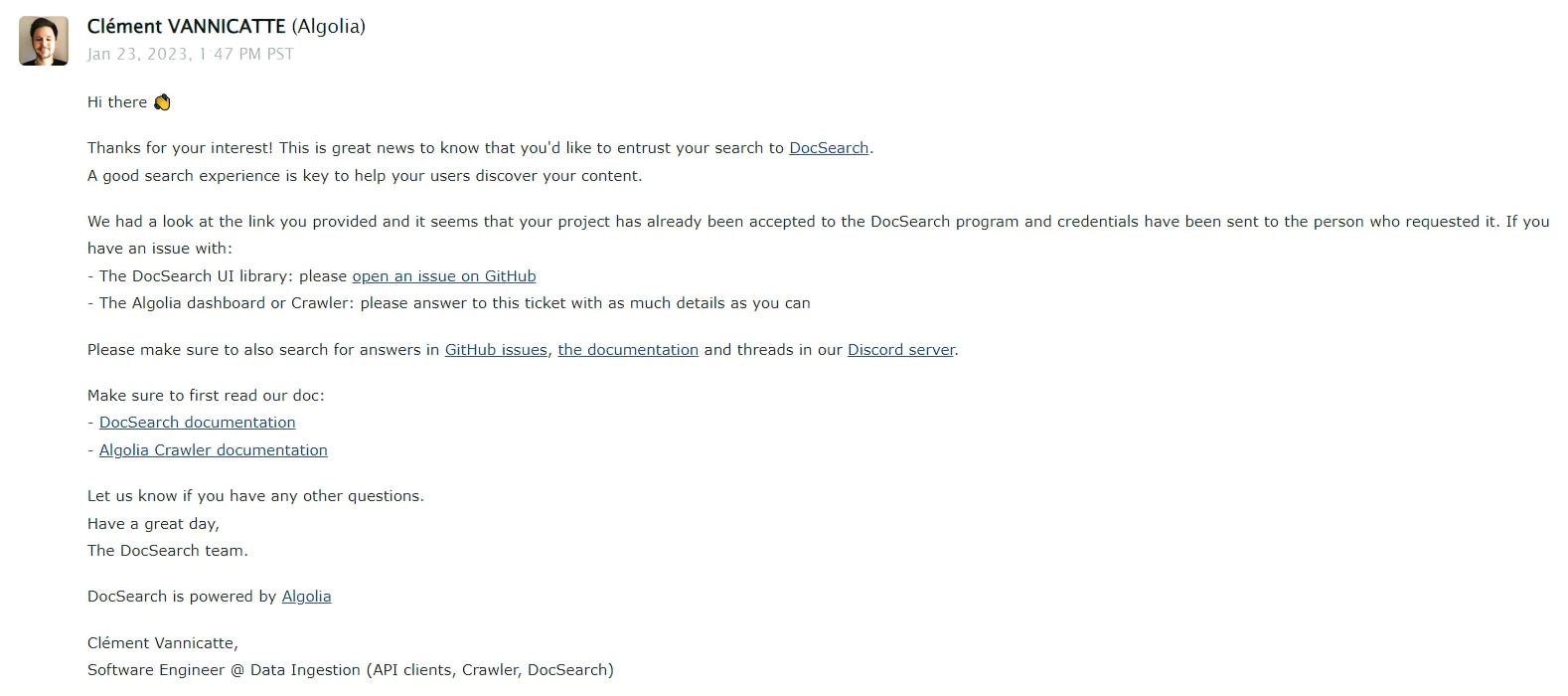
本着心急,我�又申请了一两次 (不建议这么做,因为审是人工个审核的,官方的说法是可能会延长审核周期,最长的可能会到两周!)
第二种方案
于是我又寻找到了更好也更适合我的方案,也就是上面说的第二种方案,如下:
主要参考教程的博主录制了个视频教程,可以结合文档一起参考,不过你得需要去外面的世界看看
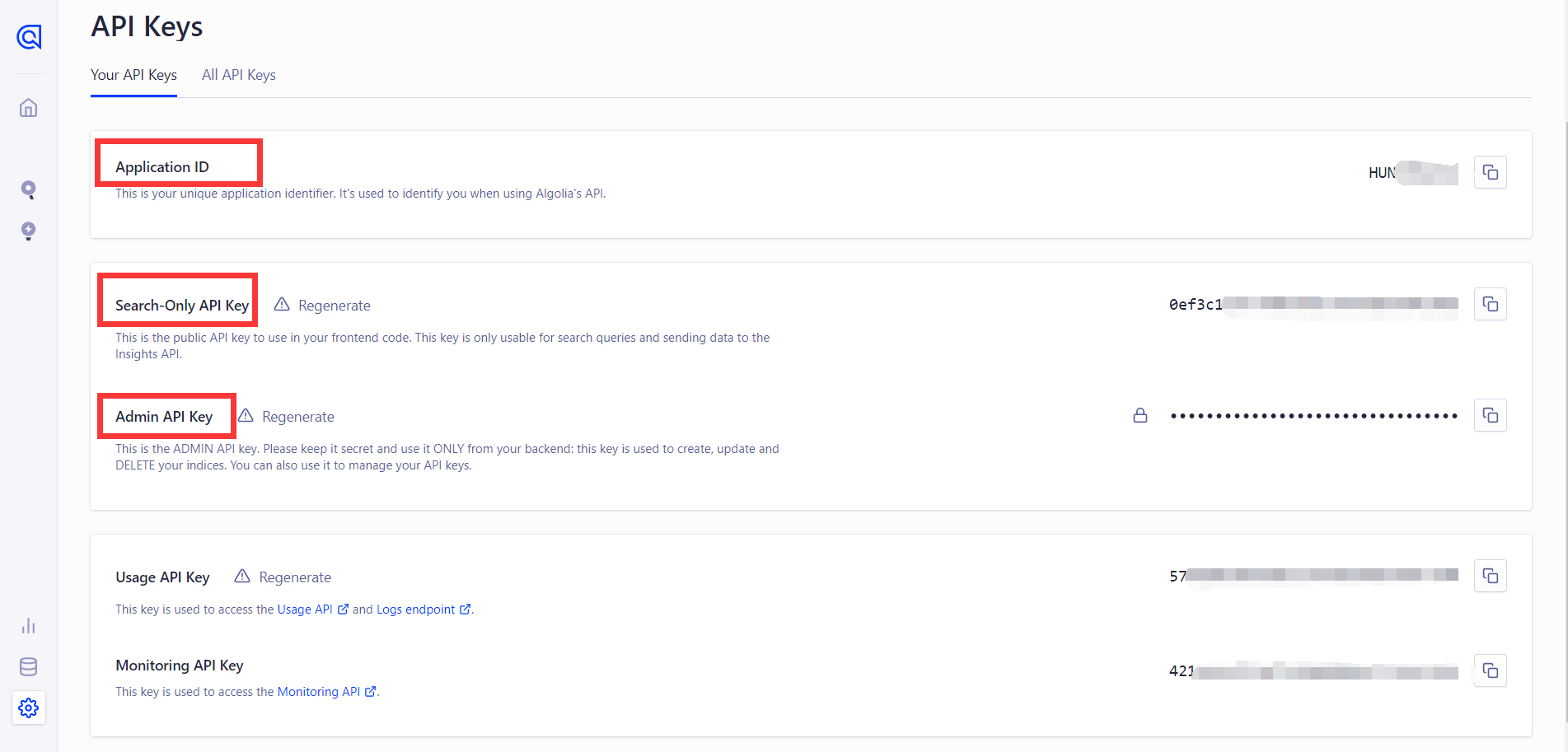
以下步骤的前提是已经创建了 algolia 账号,仓库中也创建了 Action,然后下面三个 algolia 的 Key 值是待会需要用到的
然后下面主要说其中两钟触发条件,区别在于 yml 文件的 on 字段内容不一样,其他一致,根据自己的需求选择
配置触发方式
- 提交代码触发
- 部署触发
- 定时触发
on:
push:
branches:
- main
提交代码触发相当于还没部署更新的内容就开始运行爬虫了,就是说爬取的是上一次部署成功的内容
on:
deployment
- name: Get the content of docsearch.json as config
id: algolia_config
run: echo "::set-output name=config::$(cat docsearch.json | jq -r tostring)"
- name: Run algolia/docsearch-scraper image
env:
ALGOLIA_APP_ID: ${{ secrets.ALGOLIA_APP_ID }}
ALGOLIA_API_KEY: ${{ secrets.ALGOLIA_API_KEY }}
CONFIG: ${{ steps.algolia_config.outputs.config }}
run: |
docker run \
--env APPLICATION_ID=${ALGOLIA_APP_ID} \
--env API_KEY=${ALGOLIA_API_KEY} \
--env "CONFIG=${CONFIG}" \
algolia/docsearch-scraper
on:
schedule:
# 约每天早上8点触发(UTC时间0点)
- cron: '0 0 * * *'
在根目录下 .github/workflows/ 下创建 docsearch.yml 文件
# This workflow will do a clean installation of node dependencies, cache/restore them, build the source code and run tests across different versions of node
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-nodejs-with-github-actions
name: docsearch
on:
# The way you choose
jobs:
algolia:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Get the content of docsearch.json as config
id: algolia_config
run: echo "::set-output name=config::$(cat docsearch.json | jq -r tostring)"
- name: Run algolia/docsearch-scraper image
env:
ALGOLIA_APP_ID: ${{ secrets.ALGOLIA_APP_ID }}
ALGOLIA_API_KEY: ${{ secrets.ALGOLIA_API_KEY }}
CONFIG: ${{ steps.algolia_config.outputs.config }}
run: |
docker run \
--env APPLICATION_ID=${ALGOLIA_APP_ID} \
--env API_KEY=${ALGOLIA_API_KEY} \
--env "CONFIG=${CONFIG}" \
algolia/docsearch-scraper
然后在项目仓库(我的是源码仓库)中新建两个 Action secrets ,输入 algolia 的相关 Key
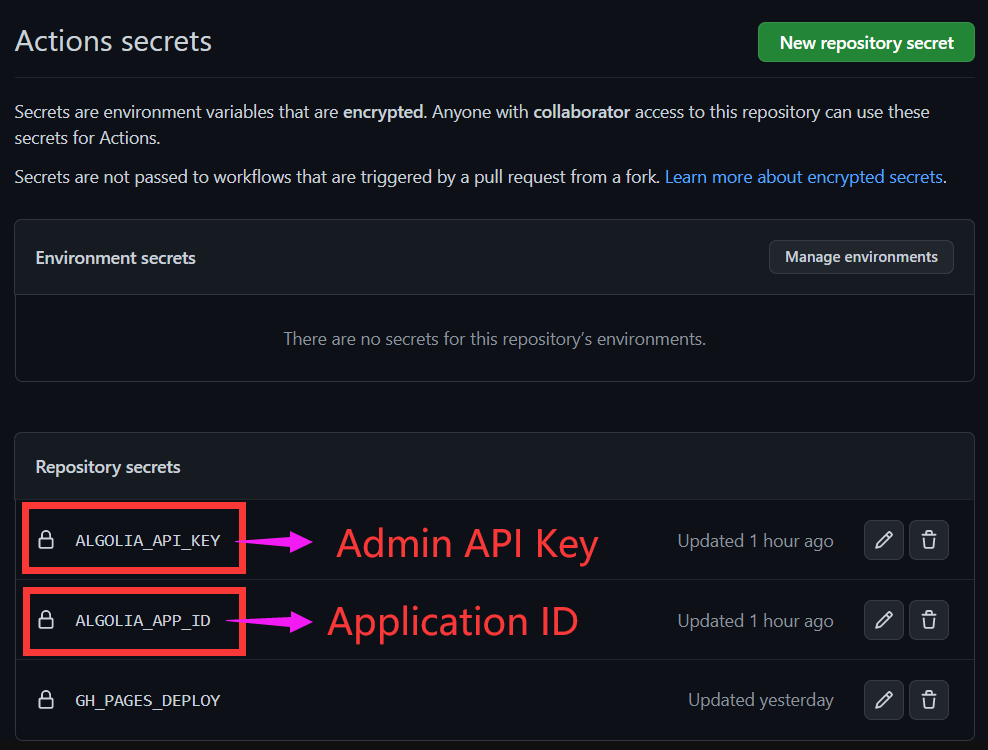
配置 docsearch.json
在项目根目录下创建 docsearch.json 文件,并将代码高亮的部分替换成自己的信息
{
"index_name": "Shake",
"start_urls": ["https://www.shaking.site/"],
"sitemap_urls": ["https://www.shaking.site/sitemap.xml"],
"selectors": {
"lvl0": {
"selector": "(//ul[contains(@class,'menu__list')]//a[contains(@class, 'menu__link menu__link--sublist menu__link--active')]/text() | //nav[contains(@class, 'navbar')]//a[contains(@class, 'navbar__link--active')]/text())[last()]",
"type": "xpath",
"global": true,
"default_value": "Documentation"
},
"lvl1": "header h1, article h1",
"lvl2": "article h2",
"lvl3": "article h3",
"lvl4": "article h4",
"lvl5": "article h5, article td:first-child",
"lvl6": "article h6",
"text": "article p, article li, article td:last-child"
},
"custom_settings": {
"attributesForFaceting": [
"type",
"lang",
"language",
"version",
"docusaurus_tag"
],
"attributesToRetrieve": [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type"
],
"attributesToHighlight": ["hierarchy", "content"],
"attributesToSnippet": ["content:10"],
"camelCaseAttributes": ["hierarchy", "content"],
"searchableAttributes": [
"unordered(hierarchy.lvl0)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy.lvl6)",
"content"
],
"distinct": true,
"attributeForDistinct": "url",
"customRanking": [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)"
],
"ranking": [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom"
],
"highlightPreTag": "<span class='algolia-docsearch-suggestion--highlight'>",
"highlightPostTag": "</span>",
"minWordSizefor1Typo": 3,
"minWordSizefor2Typos": 7,
"allowTyposOnNumericTokens": false,
"minProximity": 1,
"ignorePlurals": true,
"advancedSyntax": true,
"attributeCriteriaComputedByMinProximity": true,
"removeWordsIfNoResults": "allOptional",
"separatorsToIndex": "_",
"synonyms": [
["js", "javascript"],
["ts", "typescript"]
]
}
}
配置 docusaurus.config.js
module.exports = {
themeConfig: {
algolia: {
appId: 'YOUR_APP_ID', // Application ID
apiKey: 'YOUR_SEARCH_API_KEY', // Search-Only API Key
indexName: 'YOUR_INDEX_NAME' // Index name
}
}
};
完成以上所有步骤之后即可在自己的项目里进行搜索测试,在 Brows 里有数据说明已经正常爬取了
如果有其他的问题可以去逛逛底下的参考链接,说不定会有对应的解决方案。